Kubernetes RBAC: Deep Dive into Security and Best Practices
This guide explores the challenges of RBAC implementation, best practices for managing RBAC in Kubernetes,...


Sep 5, 2021
While Kubernetes offers a self-healing deployment platform, there is a fair chance a developer will run into issues that require deeper analysis and debugging to identify configuration problems.
Kubernetes supports a loosely coupled, distributed architecture by allowing an application to be broken down into smaller, granular modules—each of which can be written and managed independently. Although such an architecture brings a number of benefits, it also gets significantly complex to pinpoint the root cause of a bug in containerized applications. Moreover, Kubernetes lacks the breakpoints that help log application events for debugging, further necessitating the need for a pragmatic approach to find and resolve problems.
In this article, we’ll explore various techniques, best practices, and efficient tools for component-level debugging of a Kubernetes cluster.
The distributed nature of Kubernetes clusters presents a novel set of challenges when it comes to debugging containerized applications. One of the biggest issues is exposing ports on the cluster that an Integrated Development Environment (IDE) or Debugger running on a local machine can connect to. This poses a security risk since the ports are exposed in the service configuration files, meaning anyone with access to the YAML can access the cluster. Additionally, as the environment variable configuration of a service is only available within the cluster, it is equally complex to create local replicas of the service for testing and debugging, and then exposing it to cluster services.
In a typical Kubernetes ecosystem, a cluster hosts numerous Pods to scale workloads. Kubernetes automation tools can replicate Pods under the hood, making it difficult for developers and administrators to track issues as they occur. On top of that, microservices-based workloads use integrations that make distributed logging and debugging unpredictable. Due to different scenarios and configurations, debugging in Kubernetes often varies depending on the workload and organization.
A rule of thumb for debugging is to always start with identifying bugs within the application’s source code. Once the application code is ruled out as the source of a bug, it’s time to test Kubernetes objects and cluster nodes.
A microservices-based application is deployed as a container inside a Pod. Being the smallest deployment object in Kubernetes, a Pod must always be the starting point for debugging the cluster. So let’s delve into methods of application debugging within the various cluster components of Kubernetes.
When an application fails, the Pods running it may often be the cause, so it’s important to first check Pod status to ensure they are running. A Pod that is failed or in a pending state necessitates further inspection. More information on a failed Pod can be retrieved using the kubectl describe pod <pod-name> command. By revealing configuration and status information of containers and Pods, this command acts as the first level of root-cause analysis to identify issues. An additional handy outcome of this command is a log of recent Pod events that often directs the troubleshooting to its next stages or problematic components of the cluster.
A Replication Controller manages Pod lifecycles and is responsible for ensuring there are enough Pod instances to run the workloads. Troubleshooting them is straightforward, as a non-functional application mostly means Pods are improperly configured. Checking events related to a particular Replication Controller may help understand why a Replication Controller can’t create Pods. This is achieved by using the command:
Services in Kubernetes are used to balance loads across Pods. In case the service is not forwarding network traffic, the first step is to verify that it actually exists via the command:
A common problem with a malfunctioning service is that of missing or mismatched endpoints. As a result, it’s important to ensure that a service connects to all the appropriate Pods by matching the Pod’s containerPort label with the service’s targetPort selector.
Some other troubleshooting practices for services include:
Both master and worker plane nodes must work optimally in conjunction to support the application in a cluster. The first step in troubleshooting and debugging the control plane is to check the status of the nodes using the kubectl get nodes command.
Healthy nodes are by default ready to accept Pods, with the Ready status indicated as True. If a node is unhealthy, you can perform further troubleshooting using the command:
The output of the above command returns various parameters of the node’s running state, including Disk Pressure, Memory Pressure, Process ID Pressure, and Network Availability.
To inspect elemental configuration faults, it is advisable to check specific event and error logs of control plane elements such as the Kube-API Server, Scheduler, and Kube-Proxy. In the event that the control plane components are deployed as services, debugging can be performed by viewing the service status via the command:
Just like master plane nodes, you should also check worker plane nodes for availability and health. To do so, you need to perform a misconfiguration analysis for control plane components running on worker nodes, such as the kubelet service. Debugging practices include checking whether nodes are running, if the optimum resources are provisioned, and if there are any networking and authentication issues with respect to the kubelet service.
Due to its distributed nature, Kubernetes employs a network-centric architecture and also exclusively relies on the Container Network Interface (CNI) to implement a standardized networking platform for any certified plugins. This requires a non-traditional approach to inject and monitor traffic between connected services.
Some common network issues to audit and control in Kubernetes include:
Here are some practices to ensure your application workload analysis and debugging in Kubernetes is a success:
Employ code-level debuggers.
Alongside the various techniques and best practices already discussed, organizations can make use of various tools that support efficient event logging, application monitoring, and debugging for Kubernetes clusters. Some of the most popular tools include:
Rookout: Helps developers test code in containers by creating code breakpoints inside an additional debugging layer
As every function of a monolithic application runs within a defined process, debugging such applications is fairly straightforward. On the contrary, cloud-native applications rely on loose dependency among components, thereby causing individual functions to be a part of multiple concurrent processes. As this leads to an enormous amount of data logs that require deeper analysis, debugging application workloads in Kubernetes isn’t usually a cakewalk.
Debugging in Kubernetes is a combination of efficient auditing, analysis, and root cause identification. While doing so, the trick is always to identify the component of the cluster that is causing the malfunction. Along with following some best practices, you can implement the right set of tools and a pragmatic approach to debugging workloads in order to identify and resolve errors across each level of your Kubernetes ecosystem. Additionally, Kubernetes’ official documentation features various step-by-step debugging guides that come in handy for unknown errors or outages.
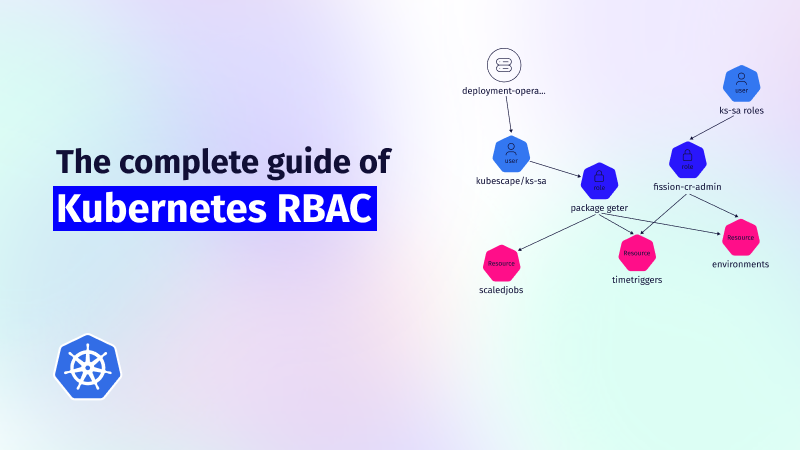
This guide explores the challenges of RBAC implementation, best practices for managing RBAC in Kubernetes,...

Role-Based Access Control (RBAC) is important for managing permissions in Kubernetes environments, ensuring that users...


In the dynamic world of Kubernetes, container orchestration is just the tip of the iceberg....
