Kubernetes Load Balancer
What is Kubernetes Load Balancer?
Load balancing is a concept where tasks are compartmentalized and distributed amongst resources such that all the resources are optimally utilized. This way any particular resource isn’t overloaded or underutilized.
Overview
In the context of Kubernetes load balancing is essentially network traffic management and resource allocation. A load balancer assigns pods, containers, and other cluster resources when it identifies an incoming request based on their availability.
Besides availability, the balancer also ensures all resources are functioning efficiently and providing expected returns in the right amount of time. Overall, the Kubernetes load balancer has three tasks:
● Distribute service requests across instances.
● Enable autoscaling based on the traffic and addition/deletion of resources.
● Ensure high availability at all times.
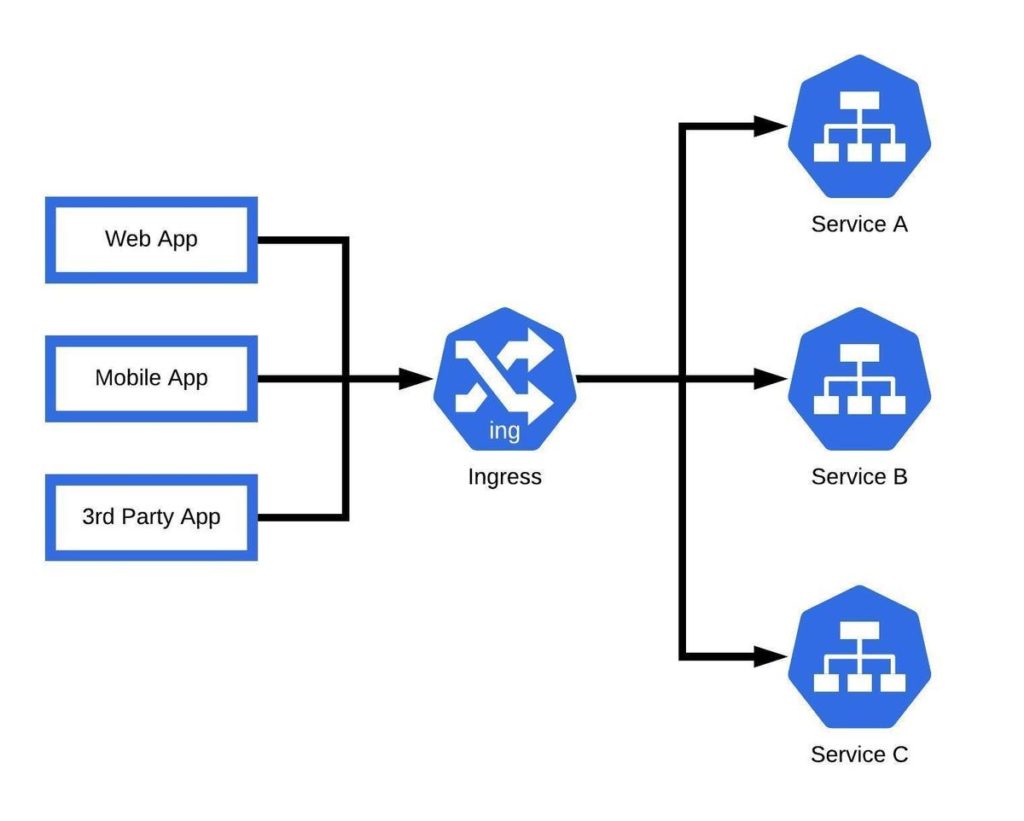
How do Load Balancers Work in Kubernetes?
Types of Load Balancers
Kubernetes primarily has two types of load balancers:
● Internal Load Balancers: These are responsible for routing requests between containers of the same Virtual Private Cloud. They also perform in-cluster load balancing and service discovery.
● External Load Balancers: These are responsible for assigning resources to incoming external HTTP Requests. Based on the availability, the set of services provided by pods and containers, the HTTP Requests are routed to specific clusters, identified by their IP addresses, and specific nodes, identified by a port number.
Algorithms Used for Load Balancing
Usually, there are multiple algorithms used to execute the process of load balancing. These algorithms are chosen by rules that fit different scenarios and are meant to prioritize and accomplish different results.
Round Robin and Its Variations
The basic Round Robin algorithm is mostly used for elemental load balancing tests because it is not dynamic in nature. Here, a set of servers will get assigned connections in an order one after the other.
This means it doesn’t account for varying speeds, the addition of resources, and other aspects. Hence a server that is slow, and a server that performs well would get the same number of connections, which isn’t efficient for running applications where real-time network traffic constantly fluctuates.
In L4 Round Robin load balancing kube-proxy uses IP tables and its rules to implement a virtual IP for services. Thus, the complexity of backend infrastructure increases with time and this causes latency. Thus, this solution isn’t scalable.
L7 proxy is used to bypass kube-proxy, thus eliminating the complexity and scaling issues. When a request arrives, the availability of pods is checked and the balancer identifies which pods are eligible. Based on this, the round robin algorithm is applied and the request is assigned.
Ring Hash
This algorithm is used in places where the clusters need to manage cache servers with dynamic content. A hash table is created with the help of a key and every time a service is assigned based on the hash value.
The number of servers doesn’t affect the hash table. Every time a new server is added, the remaining servers will give a fraction of their hits to the new one. This fraction will be determined by the number of servers. If there are 5 servers and a 6th server comes in, it will get 1/5th of the hits from each server.
A couple of use cases of this algorithm would be sticky sessions and session affinity. In real-time, this technique is used for managing shopping carts. This is because here, the same set of pods handles the specific client requests which has its disadvantages.
The workload would be highly uneven and dynamic, thus distributing that evenly amongst all resources would cause latency and inefficiency.
Fastest Response
Here the server that responds the quickest to a request will get assigned with it. This algorithm is used in processing short-lived connections.
Fewest Servers
This technique ensures that only the required number of servers are used at any given time. Any excess servers would be de-provisioned or powered down temporarily. The balancer first assigns all the requests to one server until it is at its full capacity and only then moves on to the next one.
Least Connections
This assigns requests to the servers with the least active connections. A variation of this is weighted least connections. Here, the balancer assesses how long were the active connections active, what kind of services are they handling, and more.
Based on this, the balancer handles unhealthy and slow servers and efficient servers differently. The adaptability of this algorithm is incredible since it can work with both short-lived and long-lived connections.
Least Load
Like least connections here the server with the least load is the criteria. The load can be measured in kilobytes (kb). If the server is lighter, it will get a request assigned irrespective of how many connections are currently running.
Benefits of Load Balancing
The key benefits of load balancing in Kubernetes include:
● Handling high traffic during peak hours. This way the requests are handled in the most efficient way and latency doesn’t affect the end-users.
● Avoiding bottlenecks at any point load balancers enable the shifting of traffic.
● Predicting traffic behavior based on historical data, where some load balancers can also suggest corrective action.
● Assigning alternate servers whenever certain servers are down or maintenance operations occur.
● Maintaining system speed even running two different versions of the same application.
Example of Kubernetes Load Balancer
Google Kubernetes Engine has an in-built Ingree Load Balancer. The service uses an HTTPS load balancer and allows you to define how traffic will reach the various services and can give a single IP address to multiple services in a cluster. Beyond this, the integration with Google Cloud Services makes the complete process simpler and more efficient.
Summary
Overall, a load balancer is an imperative need for K8 clusters because they ensure that the infrastructure functions at maximum efficiency at all times irrespective of the traffic behavior.