

Kubernetes RBAC: Deep Dive into Security and Best Practices
This guide explores the challenges of RBAC implementation, best practices for managing RBAC in Kubernetes,...


Feb 9, 2022
At the core of Kubernetes is the notion of high availability, meaning that every part of the system is redundant so it can continue to function despite failures. This includes multiple worker nodes to run your workload, apps are written to be able to run as multiple pods, and even the control plane will work across a cluster of machines.
In this article, we’ll explain the different ways to manage network traffic in the Kubernetes cluster. We’ll also look at the various types of services available in Kubernetes for network administration and their corresponding use cases.
In the pre-Kubernetes era, opening an application to the public internet was simple. You would rent a VM, or a bare-metal server, install all of your internet-facing services within it, and point an FQDN (such as www.example.com) to the public IP address of the server. The backend services were within a private network, such as 10.X.X.X ranges.
This archaic model of DNS pointing doesn’t work with Kubernetes. In the new model, a microservice runs simultaneously on multiple nodes containerized within multiple pods, which can be created and destroyed dynamically. So, we need a better way to manage services and the communication between them.
Containers are the basic constructs in modern application deployment. Hence, the lifecycle management of containers is essential. To develop an intuition for Docker containers, Kubernetes, and its deployment models, here are some prerequisite understandings you should develop:
As an example, we have a containerized Express.js app that listens for HTTP requests on /endpoint1 on port 80 and responds with the string: Hello, World!
In the next section, we’ll explore different ways to deploy this simple application on Kubernetes. We’ll use DigitalOcean’s Kubernetes, but you can use any cloud vendor of your choice.
In the examples below, we have a cluster with three worker nodes. If you want to follow along, you can create a similar cluster and install kubectl on your local machine, then connect it to your cluster.
A “service” is a Kubernetes object that represents the set of logical pods where an application or components are running.
$ kubectl create deployment my-deployment –image=iod-image/example-app –replicas=3
We can now list the underlying pods for this deployment by running the following command:
$ kubectl get pods -l=app=example-deployment
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-deployment-6656689554-47jjf 1/1 Running 0 7m28s 10.244.2.3 worker-01 <none> <none>
[Two more similar rows]
If you were to log in to any of the nodes of your cluster to make an HTTP request of one of the IP addresses listed above, your app would respond:
$ curl 10.244.2.3:2368`
Hello, World!
This is a very simple pod that listens on port 2368 for HTTP requests and responds with Hello, World!
Let’s suppose that the deployment above is needed by a set of other pods running inside the cluster. It wouldn’t make sense to list all the pods running the example-deployment app, get their IPs, and then direct all the dependencies to listen on those specific IPs.
Instead, we’ll expose the pods as a service backed by a single IP address. This service distributes the incoming network traffic to all the pods. It also allows pods to die and be replaced without making the entire service go down.
Depending on the use case, Kubernetes allows us to have several different types of services. These include internal services, load balancers, and NodePorts.
These services can only be accessed from within the Kubernetes cluster. For example, the service we created above was internal. It could be accessed through any of the other services, pods, and Kubernetes objects in the same namespace as that service.
Services can be exposed to the outside world via multiple mechanisms, including load balancers. Load balancers are generic networking services provided by your cloud host that can direct network traffic to different VMs in the cloud.
For example, you can have a traditional application running multiple AWS EC2 instances and use AWS’ Elastic Load Balancing to distribute the traffic across them. They are an easy way to horizontally scale your application.
The Kubernetes LoadBalancer service type uses this very LoadBalancer to allow the external requests to pods inside the Kubernetes cluster. Every managed Kubernetes distribution—like EKS from Amazon, DOKS from DigitalOcean, or AKS by Azure—will all spin up a load balancer specific to their cloud.
To create a LoadBalancer type service, use the following command:
$ kubectl expose deployment my-deployment –type=LoadBalancer –port=2368
This will spin up a load balancer outside of your Kubernetes cluster and configure it to forward all traffic on port 2368 to the pods running your deployment.
As the name suggests, a NodePort service type listens on a specific networking interface via the nodes backing the service. This is helpful for leveraging the network connectivity of each of the nodes.
To expose a deployment as a NodePort service, use the following command:
$ kubectl expose deployment my-deployment –type=NodePort
This exposes the deployment at a random port number on all the nodes that are running it:
$ kubectl get service my-deployment
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-deployment NodePort 10.245.196.255 <none> 2368:32492/TCP 5m22s
Now you can access the service at any node’s IP address (public or private) at port number 32492.
Services are good for general-purpose workloads because you can expose any networking protocol and any kind of workload, and the Kubernetes service will handle its traffic for you. That said, much of the web is HTTP(S).
Kubernetes Ingress supports routing HTTP traffic from outside the cluster to services within the cluster. As an example, you can map the /login route and send its traffic to a service that exclusively manages user logins.
This allows developers to deliver software as microservices. Path-based routing also simplifies the cluster management for people in Ops who are smoothing over the whole process.
An Ingress controller is a Kubernetes add-on that directs incoming traffic (from a source like an external load balancer) to different HTTP routes in the Ingress resources. The job of the ingress controller is to abstract away all the complexity that comes with managing HTTP routes.
If you don’t deploy an Ingress controller in your cluster, creating any Ingress resource type will do nothing.
Note that managed Kubernetes clusters will often deploy external load balancers to support the installation of an Ingress controller.
Nginx offers a server packaged as a controller manager. This is what we’ll be deploying to our cluster. The instructions are different depending on your environment, so follow the installation guide to get the proper YAML file for the installation. You can also use Helm Charts to deploy the Ingress controller.
Since we’re using DigitalOcean’s Kubernetes cluster, we’ll use the following command:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.0.4/deploy/static/provider/do/deploy.yaml
This will provision a load balancer with your cloud provider to act as a point of entry into the cluster. We can also set the replicaCount of the controller pod instance for better resiliency.
$ kubectl get pods –namespace=ingress-nginx
NAME READY STATUS RESTARTS AGE
ingress-nginx-controller-568764d844-fr79z 1/1 Running 0 31m
..
..
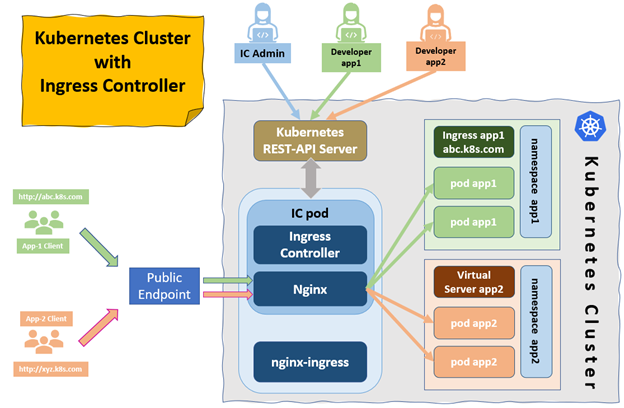
Apart from Nginx, there are many third-party solutions available, including HAProxy Ingress, Voyager, Kong Kubernetes Ingress Controller, Skipper, and Istio—to name a few.
There are three different types of Ingress controllers: open source, native, and commercial. Depending on our requirements, we can opt for any type of Ingress controller in our cluster.
There are many ways to bring network traffic to the cluster, and Kubernetes services and Ingress controllers play a vital role among them. Ingress consolidates the routing rules in a single resource to which the controller listens. By putting Ingress in front of the services, we can provide HTTP routing to the workloads. However, it requires setting up the controller in your cluster.
On the other hand, services are the abstract mechanism for exposing pods in the network. Internal services are used to provide the connectivity within the cluster, and NodePort services are used for development or to provide the TCP and UDP services on their own ports as an alternative. Finally, a load balancer can handle all types of traffic and is fully managed by the cloud provider, but it’s difficult to self-host.
All of these options help Kubernetes onboard workloads quickly and efficiently, but the best application depends on each unique use case.
This guide explores the challenges of RBAC implementation, best practices for managing RBAC in Kubernetes,...

Role-Based Access Control (RBAC) is important for managing permissions in Kubernetes environments, ensuring that users...


In the dynamic world of Kubernetes, container orchestration is just the tip of the iceberg....
