





Kubernetes RBAC: Deep Dive into Security and Best Practices
This guide explores the challenges of RBAC implementation, best practices for managing RBAC in Kubernetes,...


Feb 21, 2022
If you’re reading this article, you’re probably either running a Kubernetes cluster or planning to run one. Whatever the case may be, you will most likely need to have a look at data—how to store it and how to secure it. There are different types of stored data in Kubernetes:
In this article, we will review how to deal with each of these data types in a Kubernetes cluster. Note that from the storage access and security perspectives, the Object store items and the Platform service databases are almost identical, so we will address them together.
At the level of the operating system, files are stored on filesystems, either on the filesystem of the container itself or on a mounted volume. Mounted volumes can be either ephemeral or persistent, and Kubernetes offers both.
For persistent volumes, Kubernetes offers static or dynamic provisioning. Static provisioning requires the system administrator to pre-create volumes and makes them available to the cluster; persistent volume claims will be mapped to these pre-existing volumes. Dynamic provisioning creates volumes when persistent volume claims are made; it is often used when Kubernetes is running on a cloud platform.
Another way to create a volume is via Container Storage Interface (CSI). This mechanism utilizes the Linux FUSE feature and requires a CSI driver to be installed on the node prior to the volume claim. CSI is a very flexible mechanism. It allows, for example, creating a volume that is backed by an Object Store such as AWS S3. CSI can also serve as a filter to other volumes. For example, it may turn a read/write volume into read-only.
As far as the security of the volume is concerned, the first action to perform is to ensure that volumes are mapped only to workloads that really need them. Then, you should make sure that everything that requires only reading rights is read-only. For example, it is always recommended to map the container file system as read-only. ARMO Kubescape will help identify all the containers that violate this rule.
Both ephemeral and persistent volumes can be encrypted; however, this is outside the domain of Kubernetes itself. It is managed through custom storage classes and storage drivers, which are up to the cluster administrator to create and are often specific to the platform on which Kubernetes is running. Additionally, ARMO runtime security allows you to choose what part of the file system should be encrypted, based on the individual files, folders, files types, and more sophisticated naming convention methods.
It should be noted that some volumes are actually stored on the Kubernetes worker node’s file system. The hostPath mapping-based volumes require special attention, as the same path can be used by different workloads and lead to data exposure or corruption. The hostPath mount mechanism is not recommended from a security standpoint either. It may allow attackers to gain persistence in the cluster and access node file system folders that contain security-sensitive information. ARMO Kubescape will point out all the workloads that use a hostPath mount and suggest removing them.
Your workloads will most likely need access to Object Stores and one or more databases. If you run your Kubernetes cluster in the cloud, chances are you’re using your cloud vendor’s managed Object Storage and database offerings, such as S3 and RDS from AWS. While this takes heavy volume and database management tasks off of your shoulders, it requires you to manage the access control to these resources.
Access to CSP platform services can usually be controlled by credentials/access keys or by CSP IAM mechanisms. If you use credential or access keys, the best practices would be to keep them in Kubernetes Secrets and ensure that these secrets are mapped only to the workloads that require access to the resources. CSPs will also offer to store these secrets in their Key Management Systems (KMS), but this will leave you with the question of “who is allowed to obtain this key from the KMS and where to keep the KMS access token.” Therefore, the Kubernetes-native way of doing this is to use Kubernetes Secrets.
If you decide to use CSP IAM, which can be perceived as very convenient, you should realize that the workload requiring access to a resource may end up running on any node in the cluster. Therefore, IAM will allow any node to access the resource, unless you define very specific node affiliation, which is not recommended for resource efficiency reasons. The IAM mechanism was originally designed for VMs; therefore, its usage in Kubernetes may lead to uncontrolled excessive privileges and should only be used with extreme caution and the necessary expertise.
You will usually have the ability to turn on the encryption at rest and in transit through your cloud vendor settings console. Note that some cloud vendors, like GCP, encrypt all the persistent storage by default. You should consider overriding this only if you must keep the encryption keys in your possession for regulatory reasons. Otherwise, the cloud vendor will do the job.
Passing configuration parameters to applications running in pods is usually done using ConfigMaps in Kubernetes clusters. These configuration parameters are mapped as files to the containerized applications.
The configuration data is not supposed to be confidential. Any confidential data should go into Kubernetes Secrets (see next section) or some other secrets management tool, such as HashiCorp Vault.
While the configuration data is not expected to be confidential, it may still be security-sensitive. For example, changing some URLs from https:// to http:// may cause applications to send sensitive information without TLS protection. Therefore, it is recommended to restrict access to the ConfigMaps in the cluster to only essential personnel, at least for the modification rights.
Secrets are Kubernetes objects similar to ConfigMaps, but they contain confidential data. Secrets should be encrypted at rest (please note that you might need to enable ETCD encryption manually and ensure that ETCD communicates only with a KubeAPI server over mutual TLS). Both Secrets and ConfigMaps are used to configure your workload. The main reason why Kubernetes treats them as separate objects is to allow users to assign different access rights to each object type. Needless to say, Kubernetes Secrets must be as restricted as possible, and, as opposed to ConfigMaps, even excessive read permissions can be dangerous when it comes to Secrets.
Secrets can be passed to containers either as environment variables or as mounted files. However, the best practices recommend using the files mechanism and ensuring that the Secrets are mapped only to workloads that must have access to them.
RBAC objects define what entities (such as humans or pods) are allowed to do with various Kubernetes objects. It is very important that you create sensible RBACs (ideally following the principle of least privilege) in order to secure your cluster. Otherwise, encrypting volumes and Secrets will be useless if a human or pod can access the Kubernetes API for such objects.
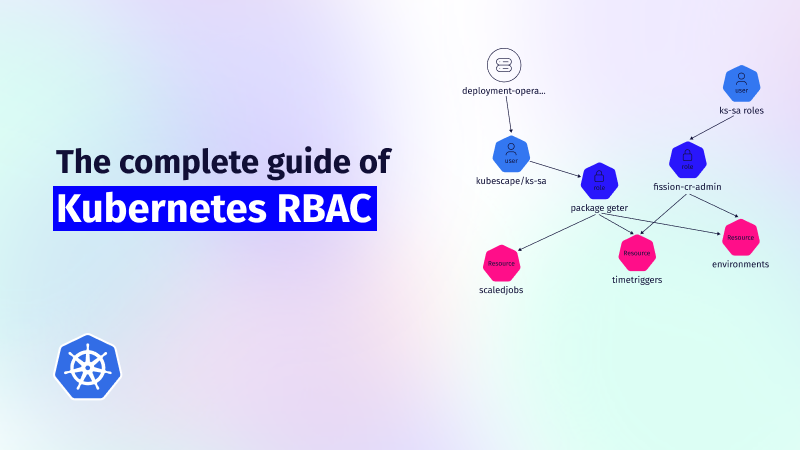
Typically, if you give too broad permissions, somebody can easily create a pod that will mount a Secret and thus have easy access to data you wanted to keep confidential. The permission to create pods is especially critical here, so spending time to create properly crafted RBAC rules should be part of your strategy for data-at-rest security. ARMO Kubescape offers an extensive RBAC visualization capability, allowing you to check who has access to which Kubernetes object and what type of access (more information here).
Kubernetes in cooperation with cloud vendor infrastructure provides flexible mechanisms for data storage and management. It is up to the users to decide which mechanism best fits their application needs. However, the security side of the data storage falls completely under the user’s responsibility. Most of the default settings are wide open and require significant security expertise to protect your applications from data leakage.
To read more about K8s best practices – check our blog Kubernetes Security Best Practices: Definitive Guide
This guide explores the challenges of RBAC implementation, best practices for managing RBAC in Kubernetes,...

Role-Based Access Control (RBAC) is important for managing permissions in Kubernetes environments, ensuring that users...


In the dynamic world of Kubernetes, container orchestration is just the tip of the iceberg....

